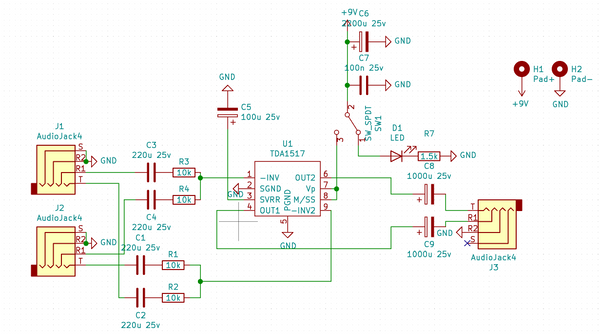
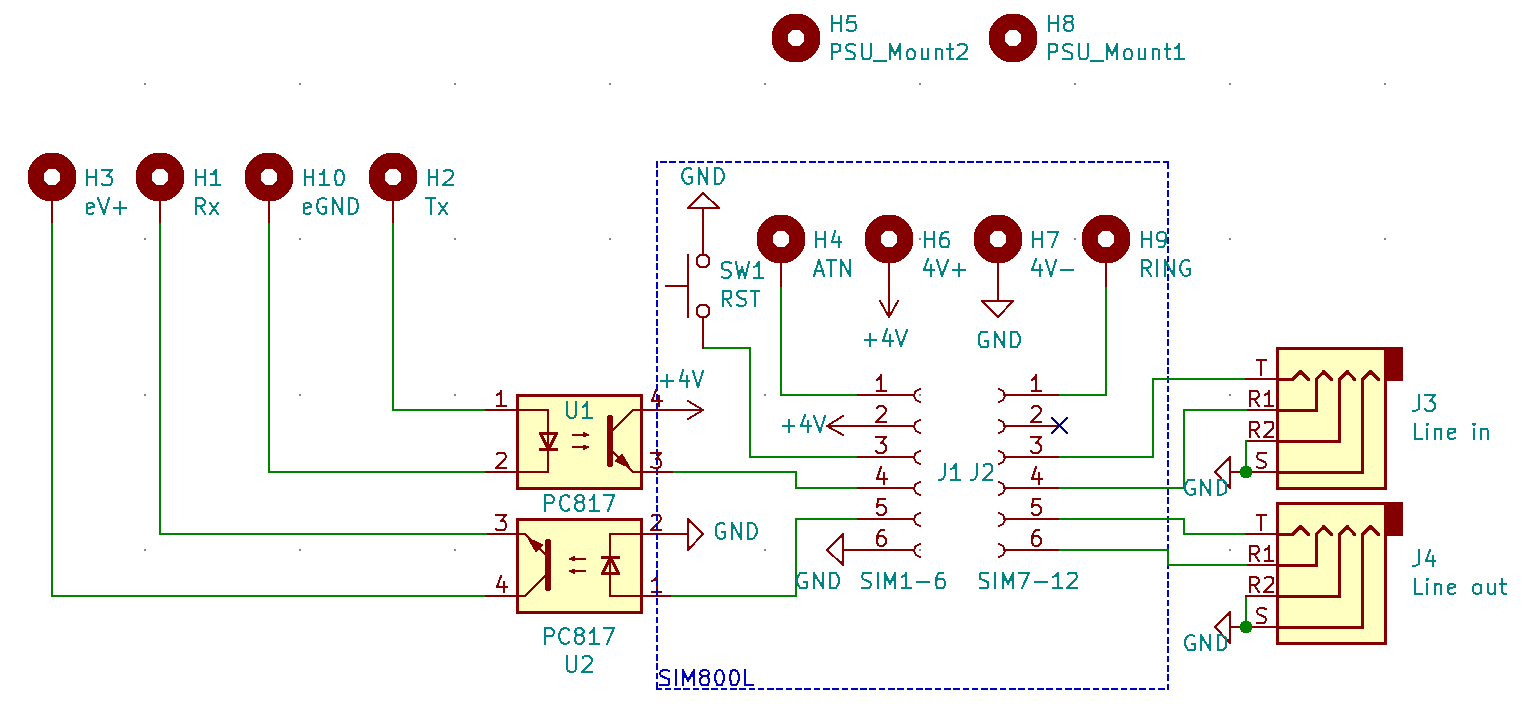
Earlier last year, I had spoken about the way we manage our invoices with our amazing invoice generator. With it's increased popularity on google it's ready for an update. Now get ready for its long-awaited, by me, successor. *drum rumble*. Invoice Manager 🎉! A better, faster and