
Real-time natural TTS

Deep Learning TTS has been a hot subject for several years now, and while the results are impressive, most of these models are way to slow to use in production.
In this article we are going to explore an end-to-end solution for TTS for near real-time, and possibly even mobile, natural sounding TTS.
This article is currently still in draft
Modern TTS
TTS in modern deep learning requires 2 main components, a text-to-mel model, and a mel-to-wav model or vocoder for short.
A mel-spectogram, here referred to as mel, is an spectogram in the mel scale. Mel spectograms are used because it stores relevant pitch information more efficiently.
The separation is made as it's nigh impossible to produce intelligible waveforms from text directly.
Text To Mel
The text-to-mel component takes to temporal problem of sound and transforms it into an spatial problem. Instead of producing raw values arccos millions of samples, it now has to produce an image. Using mels reduces our problem from "predict these millions of sequential values from text" to "predict how this 80 by 800 image will look given this text". In reality it's slightly more complicated as you still need to keep temporal consistency within those 800 pixels.
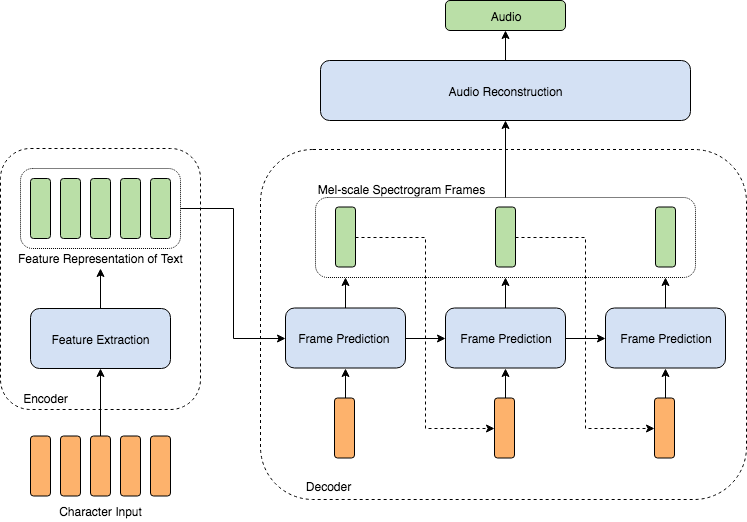
Mel to Wav
The mel-to-wav component actually already has a 'traditional' solution called the Griffin-Lim method, which is often be used as a baseline. However this is method doesn't sound very natural.
The way to improve this is to use another model to generate our wave file from our mel spectrogram. One of the first good models is WaveNet, which uses dilated causal 1D convolutions to generate new samples from previously generated samples and an MFCC. The MFCC is derived from the mel spectrogram.
Our Implementation
Transformer TTS
We use Transformer TTS for our text-to-mel model. Transformer TTS claims state-of-the-art quality while being 4x as fast as Tacotron-2.
There are faster models (FastSpeech), however it's quite a step down from the quality of Transformer TTS or Tacotron-2++.
[Train FastSpeech, misinterpreted MOS ':)]
[Code will be available soon]
[Explore distillation]
WaveRNN
WaveRNN is an alternative to WaveNet which claims a 12x inference speed improvement, with minimal to no reduction in quality. It uses GRU layers which is where the RNN part comes from.
Luckily there already is a very good WaveRNN repository available by geneing which supports pruning and real-time single-cpu inference.
The original repository was not stable in our experiments so there is an updated repository at [repo URL?]. We have done some optimizations based on auto-vectorization and also some changes based on numerical stability around softmax/tanh. We also did some profiling with perf and FlameGraph however this did not yield any new insights into optimizations.
With some hyper-parameter changes we got it to work on our (somewhat unconventionally preprocessed) dataset of LJSpeech.
In the end we created 2 models, one high-quality one which is ~0.3x real-time, and one lower-quality which is ~1x real-time.
[Pretrained?]
Real-time Inference
Even with our 2 components doing near real-time, the total runtime when experimenting is still around a lot less than real-time.
The reason for this, is that the models aren't streaming into each other. Transformer TTS has to finish creating a mel, and then WaveRNN can start working on the wav.
Both of these models support streaming, they both consume/generate one frame (row of pixels) at a time. And so feeding them into each other using streams we can actually generate near real-time high quality TTS.
Other Notes
We used the Over9000 (Radam+LAMB+LookAhead) optimizer for all models.
We trained WaveRNN without gradient clipping as it seemed to make the loss unstable.
There are slides available for a more detailed explanation of Transformer-TTS here.
Experiments
Sound Quality
[TODO]
Conclusion
[TODO]
Interested?
If you're interested in this project, want more information or an actual implementation, feel free to contact us! We are more than happy to help.